

Si vous suivez même à distance l’espace AI, vous avez probablement entendu le buzz ce week-end. Meta a abandonné sa nouvelle famille de modèles Llama 4 – malheureusement, un samedi – mais il n’y a rien de discret sur ce que ces modèles d’IA apportent à la table. LLAMA 4 est la plus grande poussée de Meta à ne pas rivaliser avec GPT, Gemini et Claude. Voici tout ce que vous devez savoir sur les modèles LLAMA 4 AI de Meta AI.

Méta libéré lama 4
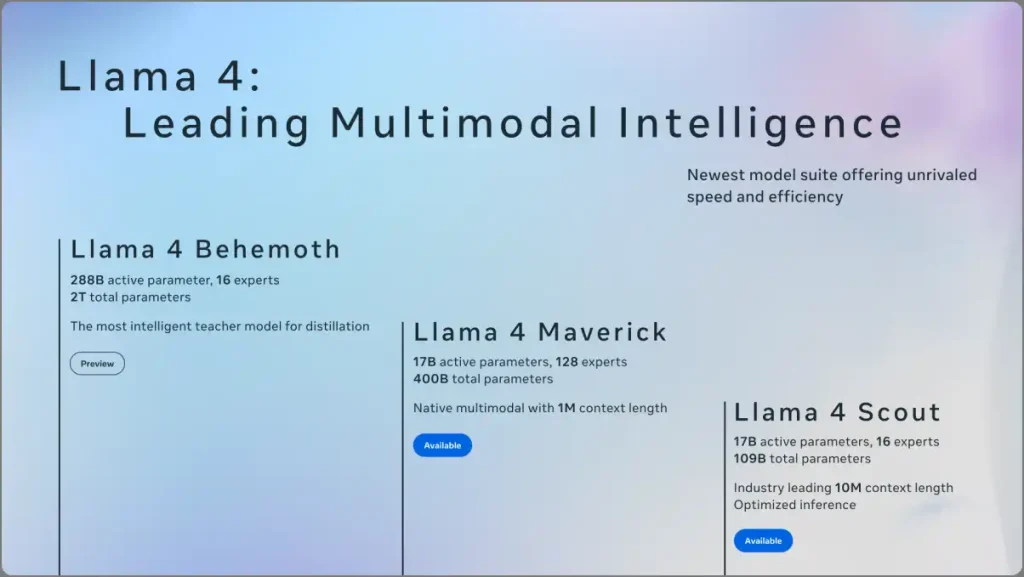
Meta a lancé trois modèles sous la collection Llama 4: Scout, Maverick et Behemoth.



- Scout: Modèle de paramètres léger, 109b
- Franc-tireur: Modèle de niveau intermédiaire, paramètres totaux 400b
- Monstre: Le plus grand modèle de méta, 2 billions de paramètres
En termes simples, les paramètres sont comme les cellules cérébrales du modèle AI. Plus un modèle a de paramètres, plus il peut comprendre d’informations, même lorsqu’il est formé sur la même quantité de données.
Cependant, pour l’instant, seuls Scout et Maverick sont disponibles. Behemoth est toujours en formation. Les modèles ont été formés sur des quantités massives de textes, d’image et de données vidéo non étiquetés pour permettre des capacités multimodales natives – oui, ces modèles comprennent à la fois le texte et les visuels à partir de zéro, similaires à d’autres modèles comme Gemini 2.0 et ChatGpt 4O.
Scout et Maverick sont ouvertement disponibles via Llama.com et des plates-formes comme Hugging Face. Ils alimentent également Meta Ai dans WhatsApp, Instagram, Messenger et l’application Web Meta AI dans 40 pays. Cependant, les fonctionnalités multimodales sont limitées aux utilisateurs anglais aux États-Unis
Quoi de neuf dans Llama 4
1. Efficace avec l’architecture du mélange d’experts (MOE)
Contrairement aux modèles denses qui utilisent chaque partie du modèle pour chaque tâche, le MOE active uniquement les «experts» en fonction de la tâche.
Par exemple, lorsque vous posez une question liée aux mathématiques, au lieu d’utiliser l’ensemble du modèle, cette architecture active uniquement l’expert en mathématiques, en gardant le reste du modèle inactif. Le modèle devient donc très efficace, rapide et peut également être rentable pour les développeurs. Cela a d’abord été popularisé par les modèles Deepseek, et maintenant, de nombreuses entreprises utilisent le MOE pour l’efficacité.
- Scout a 109B au total des paramètres, 16 experts, mais seulement 17B actifs à la fois.
- Maverick a 400B au total des paramètres, 128 experts, également 17b actifs à la fois.
- Behemoth aura 2 billions de paramètres au total, 288b actifs dans 16 experts.
2. Énorme mise à niveau de la mémoire avec d’énormes fenêtres de contexte
Scout prend en charge 10 millions de jetons en une seule entrée. Autrement dit, la fenêtre de contexte n’est rien d’autre que la mémoire que l’IA peut garder dans son esprit tout en répondant. Plus une fenêtre de contexte a une IA, plus il y a de conversations passées et de fichiers téléchargés dont il se souvient lors de la réponse à chaque question.
Auparavant, les Gémeaux avaient également l’habitude du plus haut avec seulement 1 million de jetons. Avec 10 fois la fenêtre de contexte des Gémeaux, vous pouvez désormais télécharger des bases de code entières ou même des documents longs et multiples sur le modèle Scout de Llama.
D’un autre côté, Maverick ne prend en charge que 1 million de jetons, ce qui est encore plus que suffisant pour la plupart des tâches haut de gamme.
3. Support multimodal natif
Tous les modèles Llama 4 peuvent gérer ensemble du texte et des images, similaires à d’autres modèles comme Chatgpt et Gemini. Cependant, Meta affirme que leur capacité multimodale n’est pas seulement ajoutée plus tard – elle faisait partie de la formation principale du modèle. Cela signifie que ces modèles comprennent et raisonnent sur les deux types d’entrée plus naturellement.
Cependant, nous n’avons pas suffisamment d’informations sur la façon dont Chatgpt et Gemini ont formé leurs capacités multimodales et ne savent pas à quel point ce système de fusion précoce sera utile dans le monde réel. Néanmoins, les capacités de compréhension du texte et de l’image seront bien meilleures par rapport aux modèles LLAMA précédents.
4. Performance de référence plus forte
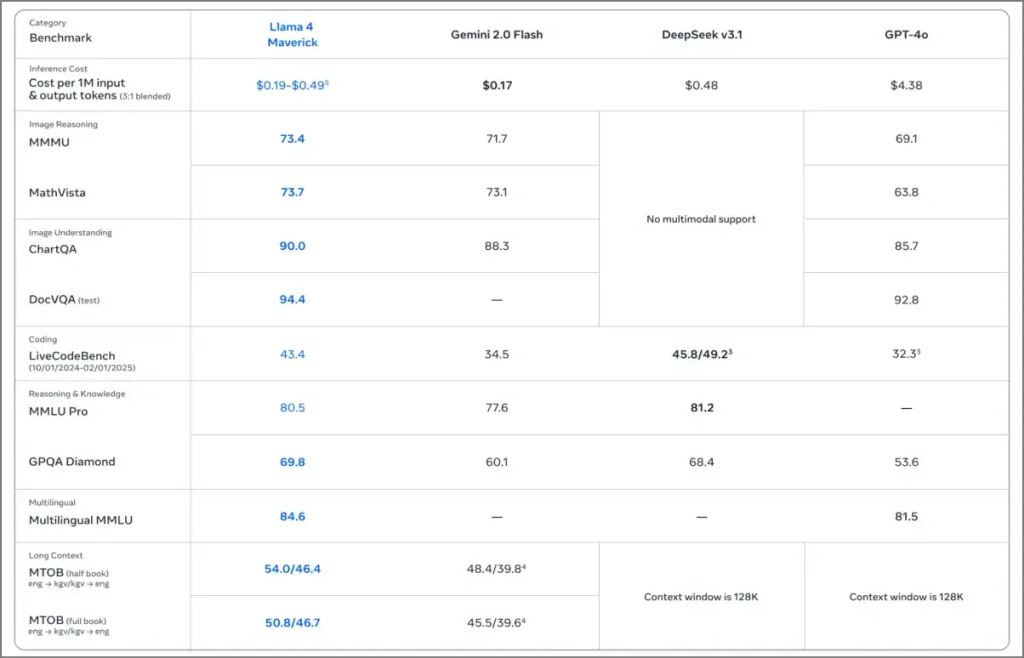
Scout bat Gemma 3, Gemini 2.0 Flash Lite et Mistral 3.1 sur de nombreux repères signalés tout en fonctionnant sur un GPU NVIDIA H100 unique. Maverick marque 1417 sur le classement Lmarena Elo, surpassant GPT-4O, GPT-4.5 et Claude Sonnet 3.7. Il tient la deuxième place au total, juste en dessous des Gemini 2.5 Pro.
Behemoth (toujours en formation) aurait battu GPT-4.5, Gemini 2.0 Pro et Claude Sonnet 3.7 dans des tests liés aux STEM.
5. Guard-rédacteur
Meta dit que Llama 4 répond plus de questions politiques et sociales qu’auparavant. Les modèles sont réglés pour être moins dédaigneux des invites «controversées» et viser à donner des réponses factuelles et équilibrées sans refus purs et simple. Une fois que Grok est devenu populaire, cela est devenu une décision courante pour de nombreuses sociétés d’IA, et j’espère que cette tendance se poursuivra.
6. Restrictions de licence
Cependant, ce n’est pas tout bon. LLAMA 4 est le poids ouvert, pas l’ouverture comme avant. Les entreprises avec plus de 700 millions de MAU ont besoin d’une autorisation spéciale. Et toute personne dans l’UE est interdit de l’utiliser ou de la distribuer en termes actuels. Quoi qu’il en soit, LLAMA est la seule IA de Big Tech ouverte et entièrement libre à utiliser, du moins pour la plupart des gens.
Meta Llama 4 AI Model LaLama
Llama 4 n’est pas seulement un pas en place – c’est la méta de la méta à Chatgpt, Grok et Gemini. Avec la multimodalité native, l’architecture MOE, le contexte plus long et les performances puissantes avec moins de paramètres actifs, Meta vise à la fois à l’échelle et à l’efficacité.
Et l’histoire n’est pas faite. Behemoth arrive toujours. D’autres mises à jour sont attendues lors de l’événement Llamacon de Meta le 29 avril. Si vous pensiez que Meta était en retard dans la course de l’IA, Llama 4 prouve qu’ils n’étaient pas seulement dedans – ils sprint.












{kind=link}