

Vous avez probablement entendu le buzz sur Deepseek R1. Il s’agit d’un modèle d’IA open source comparé aux modèles propriétaires de haut niveau comme O1 d’OpenAI. Plus que cela, c’est un modèle de raisonnement, ce qui signifie qu’il utilise une chaîne de processus de pensée pour analyser les problèmes et ses propres réponses logiquement, puis arriver lentement à une réponse. Cette approche aide le modèle d’IA à générer des réponses plus précises, en résolvant des questions complexes qui nécessitent de sérieuses compétences de raisonnement. Comme il s’agit d’un modèle open source, pour la première fois, vous pouvez installer un modèle AI de raisonnement sur votre PC et l’exécuter hors ligne. Pas besoin de s’inquiéter de la vie privée.

Dans ce guide, je vais vous montrer comment configurer Deepseek R1 localement, même si c’est votre première fois et que vous êtes nouveau dans l’exécution de modèles d’IA. Les étapes sont les mêmes pour Mac, Windows ou Linux.




Modèles que vous pouvez installer et pré-requis
Deepseek R1 est disponible en différentes tailles. Bien que l’exécution du plus grand modèle de paramètres 671b n’est pas possible pour la plupart des machines, plus petites, Des versions distillées peuvent être installées localement sur vos PC. Notez que l’exécution des modèles d’IA localement est à forte intensité de ressources nécessitant un espace de stockage, une RAM et une puissance GPU. Chaque modèle a des exigences matérielles spécifiques et voici un aperçu rapide:
| Deepseek-R1-Distill-Qwen-1.5b | 1.5b | 1,1 Go | ~ 3,5 Go | Nvidia rtx 3060 12 Go ou plus |
| Deepseek-R1-Distill-Qwen-7b | 7b | 4,7 Go | ~ 16 Go | Nvidia RTX 4080 16 Go ou plus |
| Deepseek-R1-Distill-Lama-8b | 8b | 4,9 Go | ~ 18 Go | Nvidia RTX 4080 16 Go ou plus |
| Deepseek-R1-Distill-Qwen-14b | 14B | 9 Go | ~ 32 Go | Configuration multi-GPU (par exemple, Nvidia RTX 4090 x2) |
| Deepseek-R1-Distill-QWEN-32B | 32b | 20 Go | ~ 74 Go | Configuration multi-GPU (par exemple, Nvidia RTX 4090 x4) |
| Deepseek-R1-Distill-Lama-70b | 70b | 43 Go | ~ 161 Go | Configuration multi-GPU (par exemple, Nvidia A100 80 Go x2) |
| Deepseek-R1 | 671b | 404 Go | ~ 1 342 Go | Configuration multi-GPU (par exemple, NVIDIA A100 80GB X16) |
C’est mieux si vous avez plus de RAM. En fait, nous vous recommandons d’ajouter un RAM puissant si possible pour obtenir de meilleurs résultats.
Conseil de pro: Début et confus sur le modèle R1 à installer. Nous vous recommandons d’essayer d’installer le Modèle de paramètres 1,5b le plus petit (Le premier dans le tableau ci-dessus) – il est léger et facile à tester.
Comment installer Deepseek R1 localement
Il existe différentes façons d’installer et d’exécuter les modèles Deepseek localement sur votre ordinateur. Nous partagerons quelques-uns faciles ici.
Conseil de pro: Nous recommandons Méthodes Olllama et Chatbox Si vous débutez et souhaitez un moyen facile d’installer le modèle R1 Deepseek ou n’importe quel modèle d’IA d’ailleurs.
Méthode 1: Installation de R1 à l’aide d’Olllama et de Chatbox
C’est le moyen le plus simple de commencer, même pour les débutants.
Étape 1: Installer Olllama
1. Aller au Site Web Olllama et téléchargez l’installateur pour votre système d’exploitation (Mac, Windows ou Linux). Exécutez le programme d’installation et suivez les instructions à l’écran.
2. Une fois installé, terminal ouvert pour confirmer que cela fonctionne. Copier-coller la commande ci-dessous.
Olllama – Version
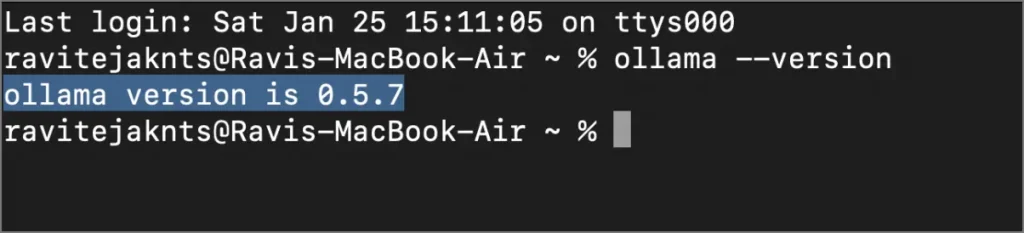
Vous devriez voir un numéro de version apparaître, ce qui signifie que Olllama est prêt à l’emploi.
Étape 2: Téléchargez et exécutez le modèle Deepseek R1
1 et 1 Donnez la commande suivante dans le terminal. Remplacer [model size] avec le modèle de l’IA que vous souhaitez installer. Par exemple, pour le modèle de paramètre 1.5b, exécutez cette commande: Olllama Run Deepseek-R1: 1.5b.
Olllama Run Deepseek-R1:[model size]
2 Attendez le téléchargement du modèle. Vous verrez des progrès dans le terminal.
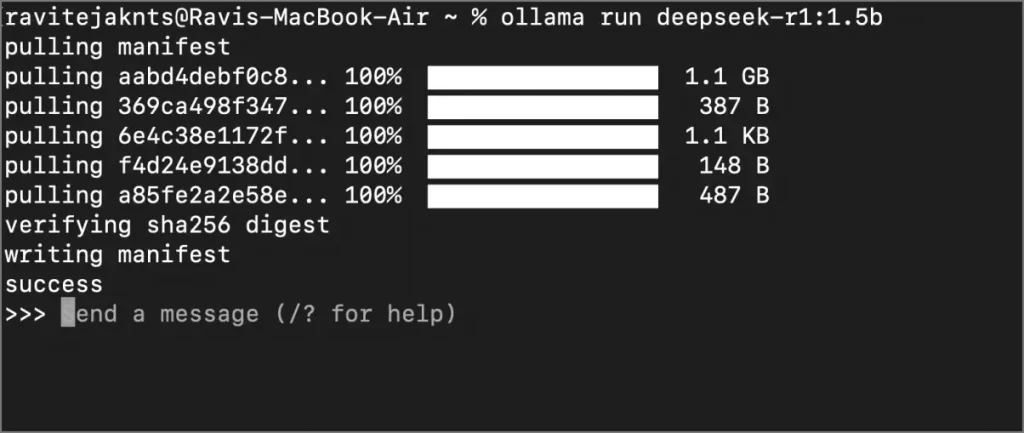
3 et 3 Une fois téléchargé, le modèle commencera à fonctionner. Vous pouvez interagir directement avec le terminal. À l’avenir, vous pouvez utiliser la même commande Terminal pour discuter avec le modèle Deepseek R1 AI.
Maintenant, nous allons montrer comment installer Chatbox pour une interface conviviale.
Étape 3: Installez Chatbox
1 et 1 Téléchargez Chatbox depuis son site officiel. Installez et ouvrez l’application. Vous verrez une interface simple et conviviale.
2. Dans Chatbox, allez à Paramètres En cliquant sur l’icône COG dans la barre latérale.
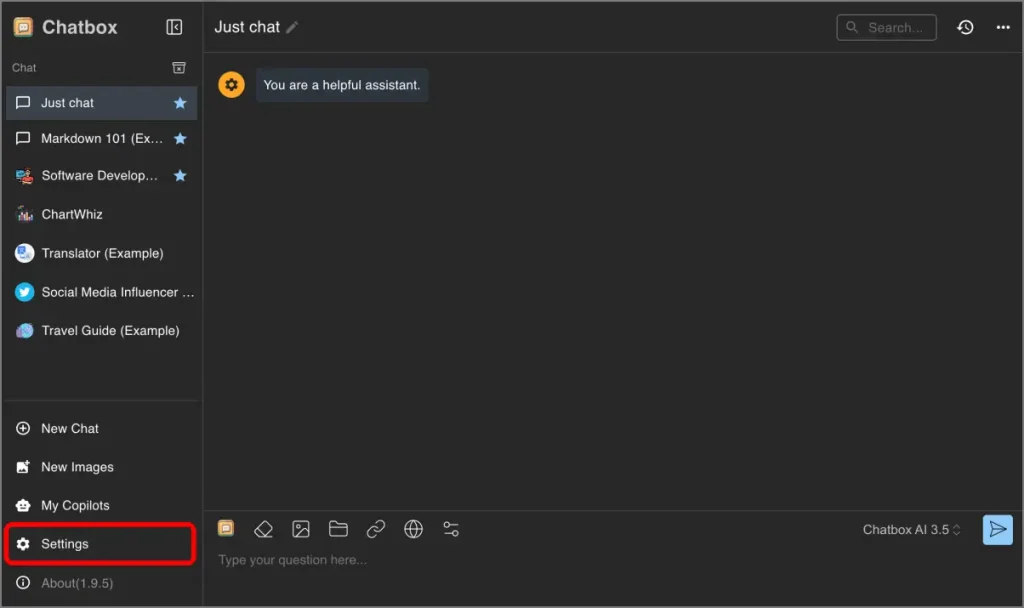
3 et 3 Définissez le fournisseur de modèles sur Ollla.
4 Définissez l’hôte de l’API pour:
http://127.0.0.1:11434
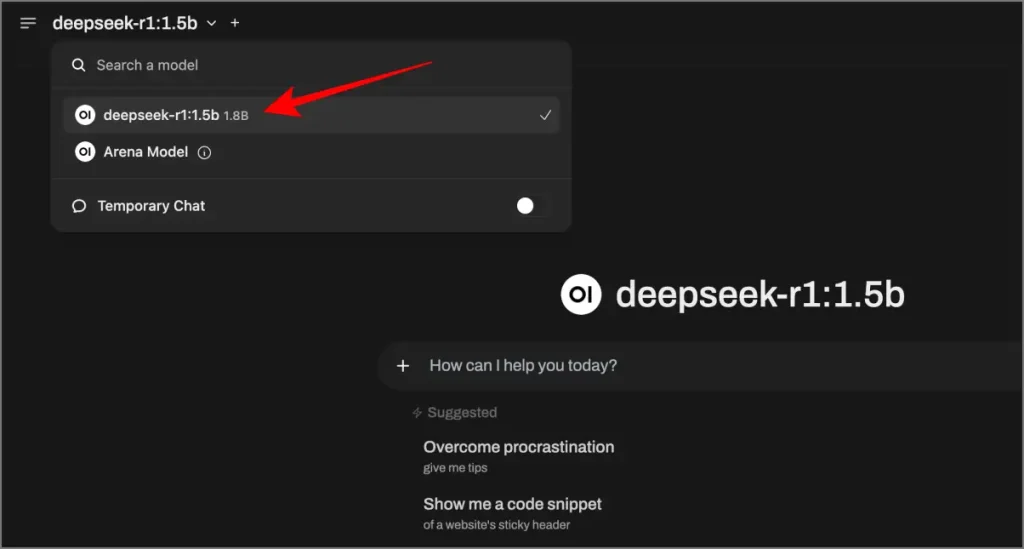
5 Sélectionnez le modèle Deepseek R1 (par exemple, Deepseek-R1: 1.5b) dans le menu déroulant.
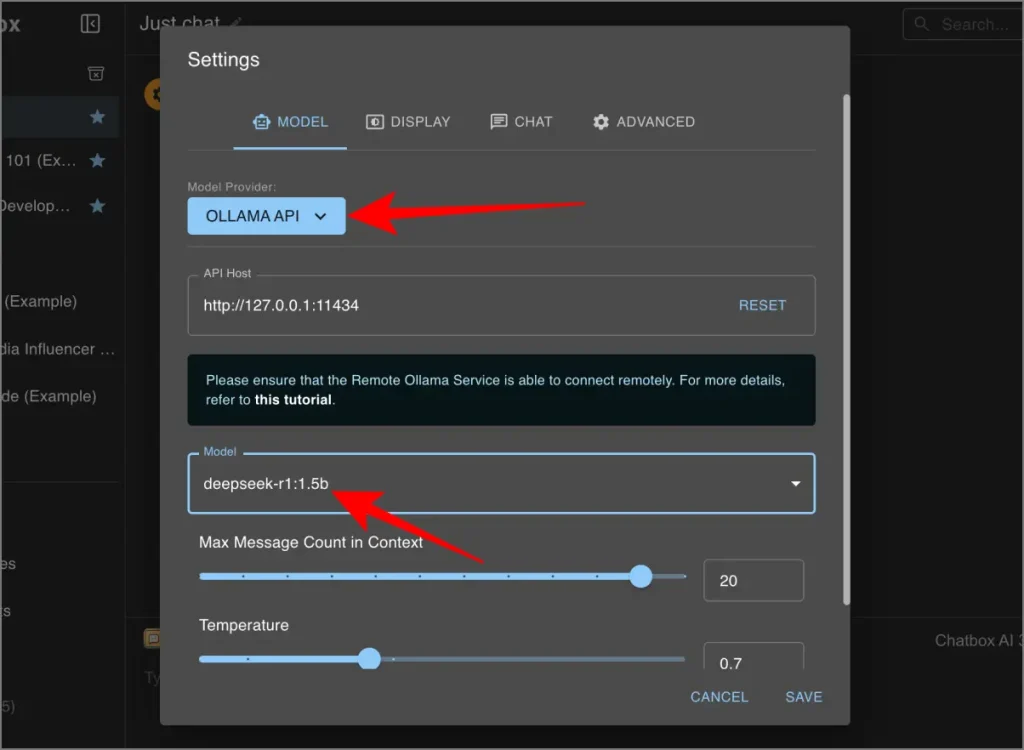
6. Frapper Sauvegarder Et commencez à discuter.
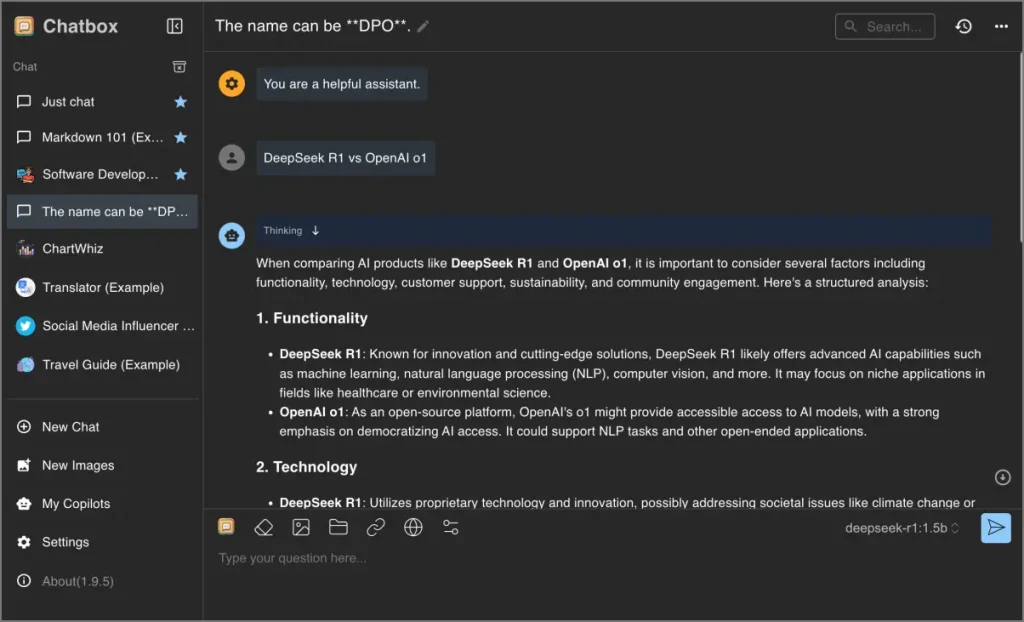
Méthode 2: Utilisation d’Olllama et Docker
Cette méthode est excellente si vous souhaitez exécuter le modèle dans un conteneur Docker.
Étape 1: Installer Docker
1 et 1 Aller au Site Web de Docker et télécharger Docker Desktop pour votre système d’exploitation. Installez Docker en suivant les instructions à l’écran.
2 Ouvrez l’application et connectez-vous avec le service.
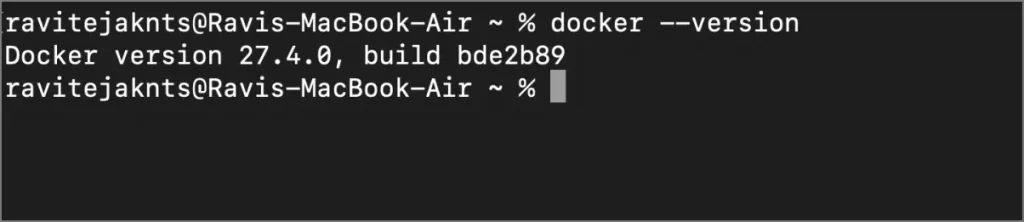
3 et 3 Tapez la commande ci-dessous dans le terminal pour l’exécuter.
Docker – Version
Vous devriez voir un numéro de version apparaître, ce qui signifie que le Docker est installé.
Étape 2: Tirez l’image Open Webui
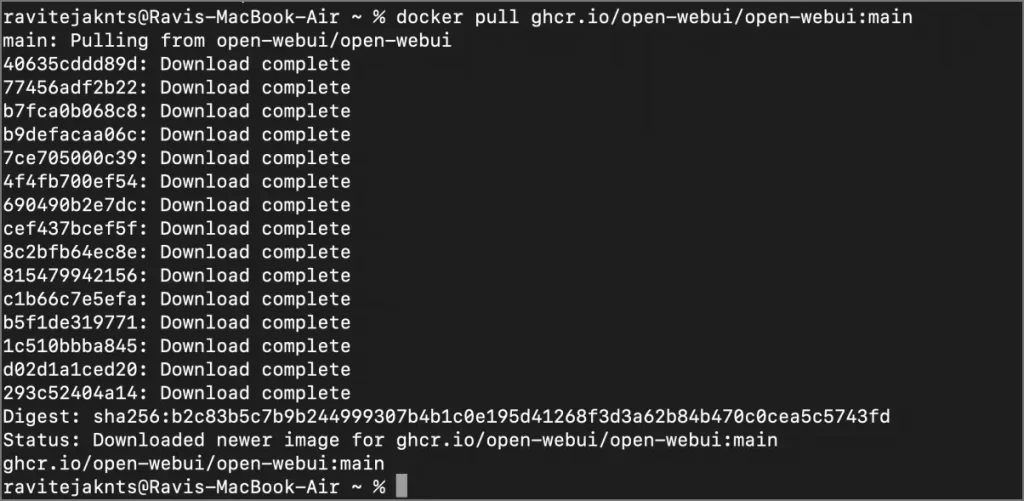
1 et 1 Ouvrez votre terminal et type:
docker tire ghcr.io/open-webui/open-webui:main
2 Cela téléchargera les fichiers nécessaires pour l’interface.
Étape 3: Exécutez le conteneur Docker et Ouvrir webui
1 et 1 Démarrez le conteneur Docker avec un stockage de données persistant et des ports mappés en exécutant:
docker run -d -p 9783: 8080 -v open webui: / app / backend / data –name open-webui ghcr.io/open-webui/open-webui:main
2 Attendez quelques secondes pour que le conteneur commence.
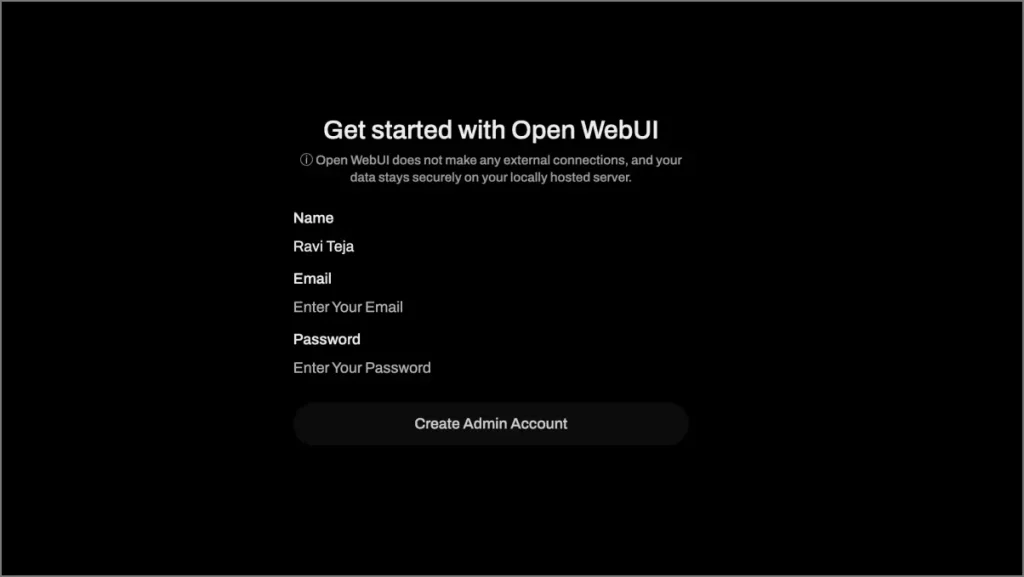
3 et 3 Ouvrez votre navigateur et allez à:
http: // localhost: 9783 /
4 Créez un compte comme invité et vous serez redirigé vers l’interface principale. À ce stade, aucun modèle ne sera disponible pour la sélection.
Étape 5: Configurer Olllama et intégrer Deepseek R1
1 et 1 Visiter le Site Web Olllama et le télécharger / l’installer.
2 Dans le terminal, téléchargez le modèle Deepseek R1 souhaité en tapant:
Olllama Run Deepseek-R1: 1.5b
3 et 3 Actualisez la page Open Webui dans votre navigateur. Vous verrez le modèle de profondeur R1 téléchargé (par exemple, Deepseek-R1: 8b) dans la liste des modèles.
4 Sélectionnez le modèle et commencez à discuter.
Méthode 3: Utilisation de LM Studio
Fonctionne très bien si vous ne souhaitez pas utiliser le terminal pour interagir avec Deepseek localement. Cependant, LM Studio ne prend actuellement en charge que les modèles QWEN 7B et 8B. Donc, si vous souhaitez installer des modèles 1.5b ou même plus élevés comme 32b, cette méthode ne fonctionnera pas pour vous.
1 et 1 Téléchargez LM Studio à partir de son site officiel. Installez et lancez l’application.
2 Cliquez sur le Icône de recherche Dans la barre latérale et rechercher le modèle Deepseek R1 (par exemple, Deepseek-R1-Distill-Llama-8b).
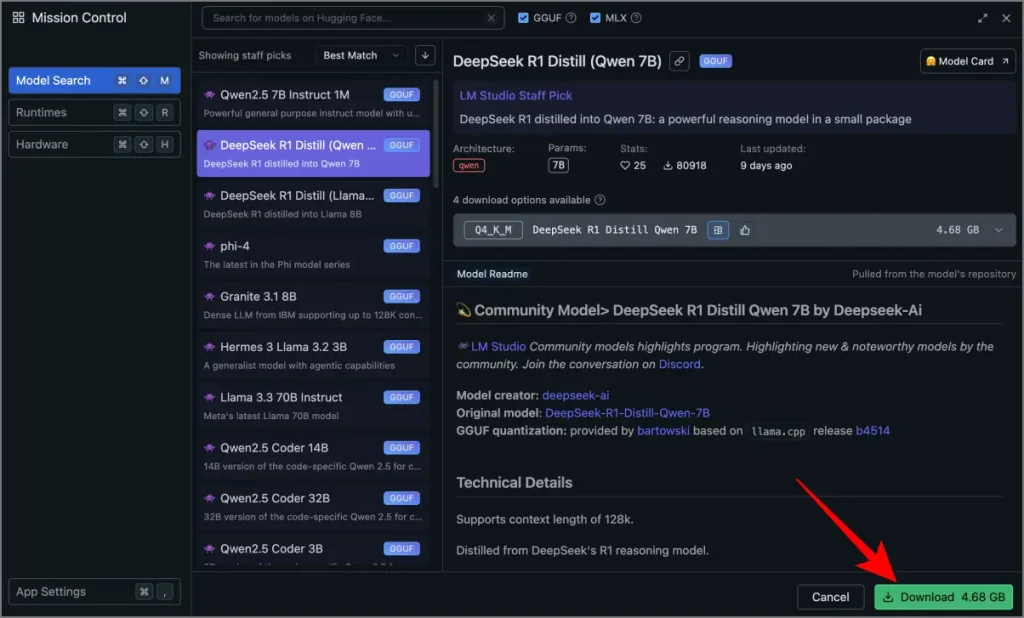
3 et 3 Faire un clic Télécharger et attendez que le processus se termine.
4 Une fois téléchargé, cliquez sur le barre de recherche Au sommet de la page d’accueil de LM Studio.
5 Sélectionnez le modèle téléchargé et chargez-le.
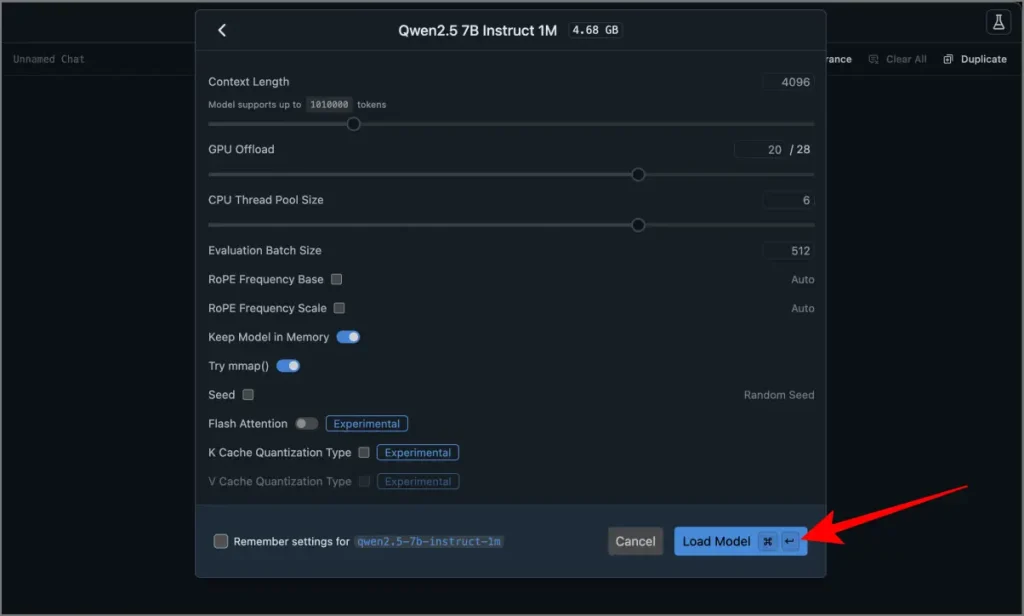
6. C’est ça. Tapez votre rapide Dans la zone de texte et frapper Entrer. Le modèle générera une réponse.
Réflexions finales
L’exécution Deepseek R1 offre localement la confidentialité, les économies de coûts et la flexibilité pour personnaliser votre configuration d’IA.
Si vous êtes nouveau dans ce domaine, commencez par Olllama et Chatbox pour une configuration simple. Docker est idéal pour les utilisateurs familiers avec la conteneurisation, tandis que LM Studio fonctionne mieux pour ceux qui évitent les commandes du terminal. Essayez un modèle plus petit comme le 8b ou 1,5b pour commencer, et acquitter au fur et à mesure.

















{kind=link}